

Use Case
The goal of this project is a smart tour guide who goes through a physical world with attractions, which you modelled before. The tour guide gives you information about the attractions by using image recognition. So, the robot should behave like a real tour guide guiding you through a city. There are several steps needed to fulfill this. In this case, the NAO robot is the tour guide.
The use cases for this project are following:
Use Case 1: Modeling Method
The NAO should get information of the city. This includes the ways and directions to walk and the location of attractions. Therefore, a model is needed, which was realized with ADOxx with the core elements streets, crosses and attractions. The model has to be exported as XML and later on can be imported again with the right information about the attractions.
Use Case 2: Movement and Interaction
The NAO should physically walk the ways and strive for the right places to take pictures of the attractions. So, the NAO should be able to walk fitted to the modelled map. Moreover, the NAO should take pictures at the right position with his integrated camera. This can be realized with the NAO SDK in Java. And finally, the NAO should interact with the human. This means, that he tells you what he is doing and what attractions are in front of you. This was also implemented in the Java code.
Use Case 3: Image Recognition
The NAO should recognize these images by using image recognition and mark them on the modelled map with the right information. Here, I used the Google Vision image recognition API, which returns an JSON file with the information of the image you sent. Google Vision gives you object related information with a percentage of certainty. It gets almost all relevant objects of the picture very precise.
Experiment
Modeling Method
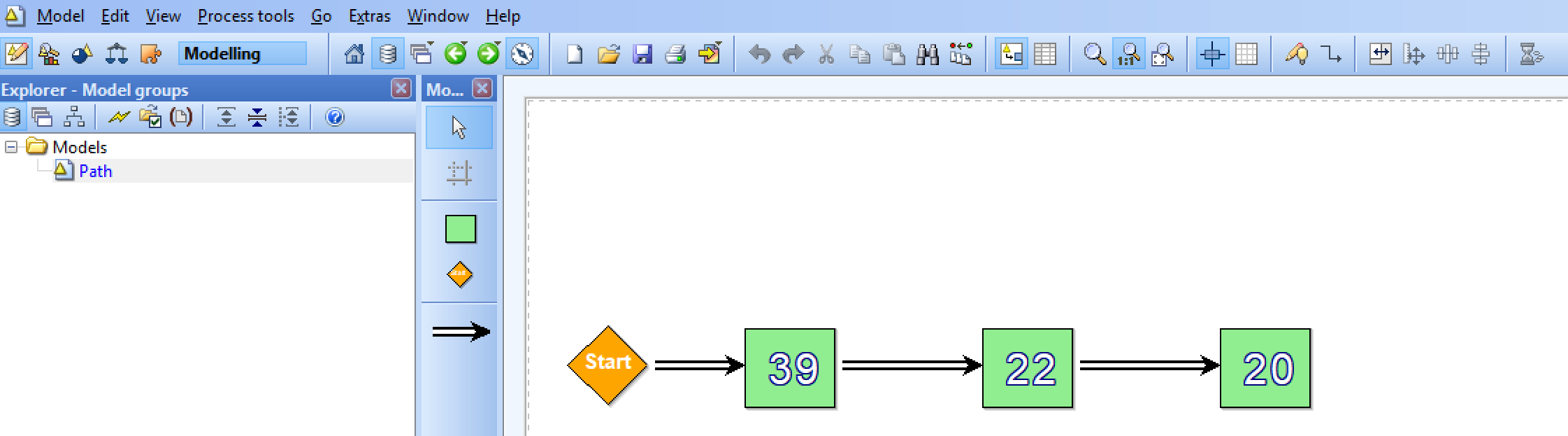
Now, I want to introduce the modelling method, which was implemented by ADOxx. ADOxx provides a modelling platform. As already described the model will be a map. The modeling method was kept simple, as it is not needed to create so many classes for these use cases and the overview will be better. On the model you can see a startpoint, in this case the starting position of the robot and the positions of the attractions connected with streets. Therefore, the classes for the modelling method are following:
Street
Roads and paths will be represented as streets. You will be able to go bidirectional ways. Moreover, you can choose if you want vertical or horizontal streets. The NAO will follow these streets.
Crossroad
At crossroads you will be able to change the direction as you wish. It depends on the connectors from the crossroad to the streets. The NAO will pick the first one he finds and explores the map.
Attraction
Attractions can be represented as buildings or other attractions. They are placed on the streets. Here, the NAO will take his pictures and later on call the API of the image recognition. This class also got attributes like AttractionName, AttractionInfo and Known/Unknown.
Here is a simple example of the model with two attractions. This model was also used for the results in the next section.
Movement and Interaction with the NAO
As I already mentioned, I implemented this project in Java. So, I used the Java Naoqi SDK to control the NAO robot.
How to connect
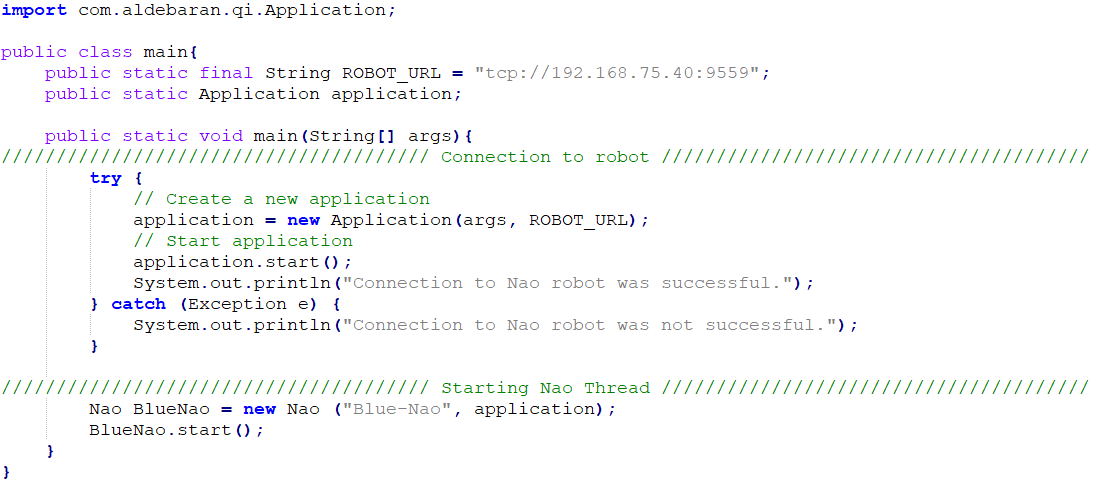
You have to be connected in the Omilab network and insert the right ROBOT_URL. In this case I took the URL of the Blue NAO.
How to start an action
You can just import Aldebaran Qi Helper, which is included in the SDK for interactions like movements or speak.

Above you can see an example how the NAO robot can speak with a string as input.
Image Recognition
For the image recognition of the taken pictures I used the Google Vision API. You can make a HTTP request containing the image, which has to be converted to Base64 format. Sadly, this service is not completely for free. The requests you make are limited per month and for more requests you will have to pay. So, you have to register at Google Vision with a payment option to receive an API key.
How to make a HTTP request to the API with type LANDMARK_DETECTION

The JSON result:

DevOps
- Import the maven project here https://gitlab.dke.univie.ac.at/edu-semtech/nao_tourguide
- Download the java-naoqi-sdk here http://doc.aldebaran.com/2-1/dev/java/index_java.html
- Add the java-naoqi-sdk to your library (Note: you need a Java Runtime Environment 32 bits, as 64 bits is not supported)
- Register here for the image recognition API https://cloud.google.com/vision/?hl=en (Note: you have to add a payment method)
- Now you can set the ROBOT_URL in the class main.java (Blue NAO presetted)
- Add your Cloud Vision API key in ImageRecognition.java
- You have to change some paths for the image and the exported XML model to your local desired location in Nao.java, XMLHandler.java and ImageRecognition.java
- Now you should able to execute the project
Results
In this video you can see the results of the project. As I wrote before, I used the example model for this video. The NAO goes through the map with two attractions. First, on the right side the Statue of Liberty and later on the left side the Eiffel Tower (apparently the NAO can walk from New York to Paris very fast). Moreover, you can also see the taken pictures by the NAO in this video.
Problems
I also have to mention, that the NAO is not very precise at walking. This means, that he can slightly miss the coordinates you gave him to walk. Another point is that on the NAO an own software is running. So, sometimes he is doing things you didn’t expected, but of course this is on purpose by the producers, as it is a humanoid robot. But all in all, the NAO is a good robot you can use for laboratory experiments.
Future Work
You can extend the modeling method as well as the interaction of the NAO robot as detailed as you wish. For example you can change the algorithm to walk or you can add hand gestures while the NAO is talking to the tourists. Moreover, in my opinion it would be nice if you add an additional API to get more detailed historical information about the attractions.